

A place to share emerging technologies and AI experiments with our publishing and marketing partners.
Register your interest for a Labs Live hackathon.
Research
LLM Arena: Who answers best?
Ozone Labs has built a simulation platform that helps publishers understand how their content performs inside AI-powered answer engines. This gives us a real-world read on which models handle current affairs best.
This first experiment shows how some different models perform on topical news questions. We used humans and AI judges in a head-to-head “which answer is better” format, and rated the models using ELO, a zero-sum-game scoring mechanism popular in the chess community:
Three AI judges independently scored 2,052 blind pairwise comparisons across 19 current-affairs questions. ELO ratings computed via Bradley-Terry maximum-likelihood estimation. Higher ELO = better performance.
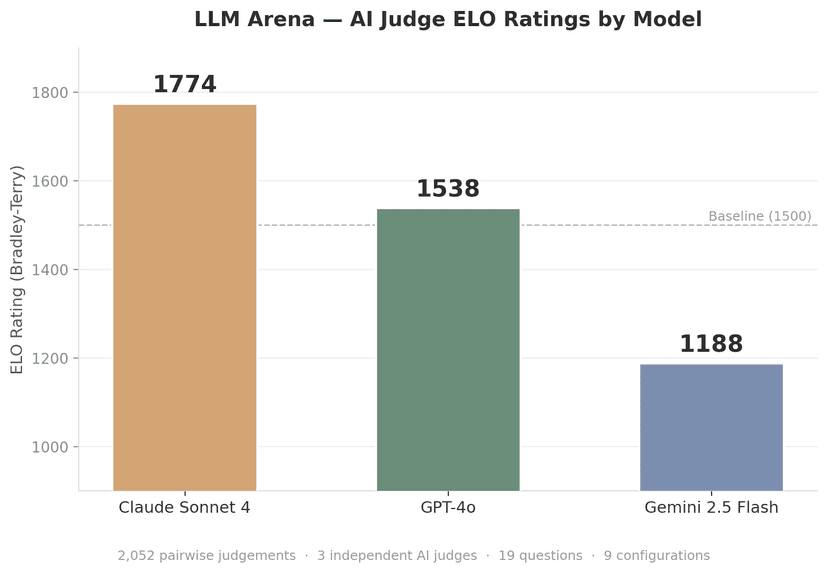
Note on Gemini 2.5 Flash results: Gemini calculates token usage differently from Anthropic and OpenAI models, which may have affected how prompts were truncated or processed. We're reviewing whether this created an unfair comparison. Treat the Gemini scores as provisional until we can confirm parity in input handling.
Methodology
We ran a blind side-by-side evaluation of three popular large language models. Each model answered 19 current-affairs questions generated from topical trend information obtained from social media, search, and other trend data. Every pairwise combination (36 pairs per question) was independently judged by three frontier models with web search grounding: Claude Opus 4, GPT-4.1, and Gemini 2.5 Pro. Each judge evaluated pairs on accuracy, completeness, clarity, and helpfulness, casting a vote for the stronger response or declaring a tie. This produced 2,052 pairwise judgements in total.
Performance ratings were computed using ELO, a maximum-likelihood method for estimating relative strengths from pairwise data. To mitigate provider self-serving bias, we deliberately chose judge models from all three providers. No systematic bias was observed. Each judge ranked its own provider's model honestly relative to the competition.
ELO is a rating system for calculating relative skill levels in zero-sum competitions. Scores computed via Bradley-Terry maximum-likelihood estimation.
Labs Live
Where impossible ideas get built
As a business originally built from great collaboration, we truly believe that the best ideas come alive when we work together with our brand, agency and publisher partners. By introducing our engineers and data scientists to the mix, we join up to solve tricky problems – from first concepts through to finished products.
Pitch ideas
Anyone can throw an idea on the table — a hunch, a frustration, a “what if.”
Form teams
Self-organise around the ideas that excite you. Engineers, commercial, data — all welcome.
Build fast
Focused sprint, usually 1–2 days. Working prototypes, not presentations.
Ship
Proven experiments graduate into products. What doesn't ship still teaches us something.
Projects
Concepts, prototypes, open source projects and stuff
While not every great idea makes it through our product development process, the exploration of that idea always uncovers lots of learnings that could be used elsewhere. In our Projects, we will show that thinking and make it available to anyone who might be able to spark another idea from what we've discovered.
Experimenting with AdCP
Last updated: 2026-03-30
AI-powered ad planning that connects Claude directly to Ozone's audience intelligence. Paste a brief, get a media plan back with real data.
Topics
Last updated: 2026-03-30
An exploration into how certain topics are categorised across different publisher titles, and how often companies, people and locations are referenced.
Stories
Last updated: 2026-03-24
Stories is an exploration into how similar articles across publisher titles organise together into related sets.
Blog
Latest from the lab
Announcements and posts for a behind-the-scenes look at what we're building.

It's a wrap for Labs Live hackathon for Ozone
2026-07-07
A short film from the participants at our Labs Live hackathon spanning locations in UK, Poland and Ethiopia. 60+ participants and more than 20 brilliant projects.
 Ozone
OzoneOzone Labs Live – Halfway update
2026-06-26
Our Chief Product Officer, Matt Townsend, gives an update halfway through our cross-business Labs Live hackathon.
 Matthew Townsend
Matthew TownsendOzone NYC outings: Beeler.Tech and AdCP announcement with Bedrock
2026-05-06
A couple of exciting NYC outings today... Firstly, our CTO Scott and Director of Customer Success & GTM Charlotte will be at Beeler.Tech's AI Publisher Response event.
 Ozone
OzoneThanks to Claude, the writing is literally on the wall
2026-05-05
I'm not a developer. I've spent most of my career in B2B marketing. My relationship with software has always been the same: I have an idea, someone else builds it or I buy it off the shelf, and sometimes it works really well (and sometimes it doesn't!).
 Bryan Scott
Bryan Scott